
I am a PhD Student at the University of Texas at Austin and Student Researcher at Google DeepMind. My PhD advisor is Ray Mooney.
Research: My research centers on grounded natural language processing, reinforcement learning, and robotics. Broadly, I am interested in creating AI systems that can understand and interact with complex environments through language and action.
Timeline: I completed my B.Sc. and M.Sc. in Computer Science at Brown University, where I was advised by Stefanie Tellex and George Konidaris in the Humans to Robots Lab. During my PhD, I was a consultant and research scientist at Blackbird.AI, where I created Compass, an agentic research and analysis application for multimodal social media content. Before my PhD, I worked at Luminoso in Boston, contributing to ConceptNet.
Fun facts: I co-created the first publicly released, open-source LLM OpenGPT-2 and dataset OpenWebText. My Erdős number is 3.
News
- [July 2026]: Our paper, MET-Bench: Multimodal Entity Tracking for Evaluating the Limitations of Vision-Language and Reasoning Models, has been accepted to ICML 2026. MET-Bench evaluates how well vision-language models maintain entity state across modalities; we find a substantial gap between text-based and image-based entity tracking that stems primarily from visual reasoning rather than perception, and show that reinforcement learning yields strong in-modality gains for open-source VLMs but does not transfer robustly across input modalities.
Publications
2026
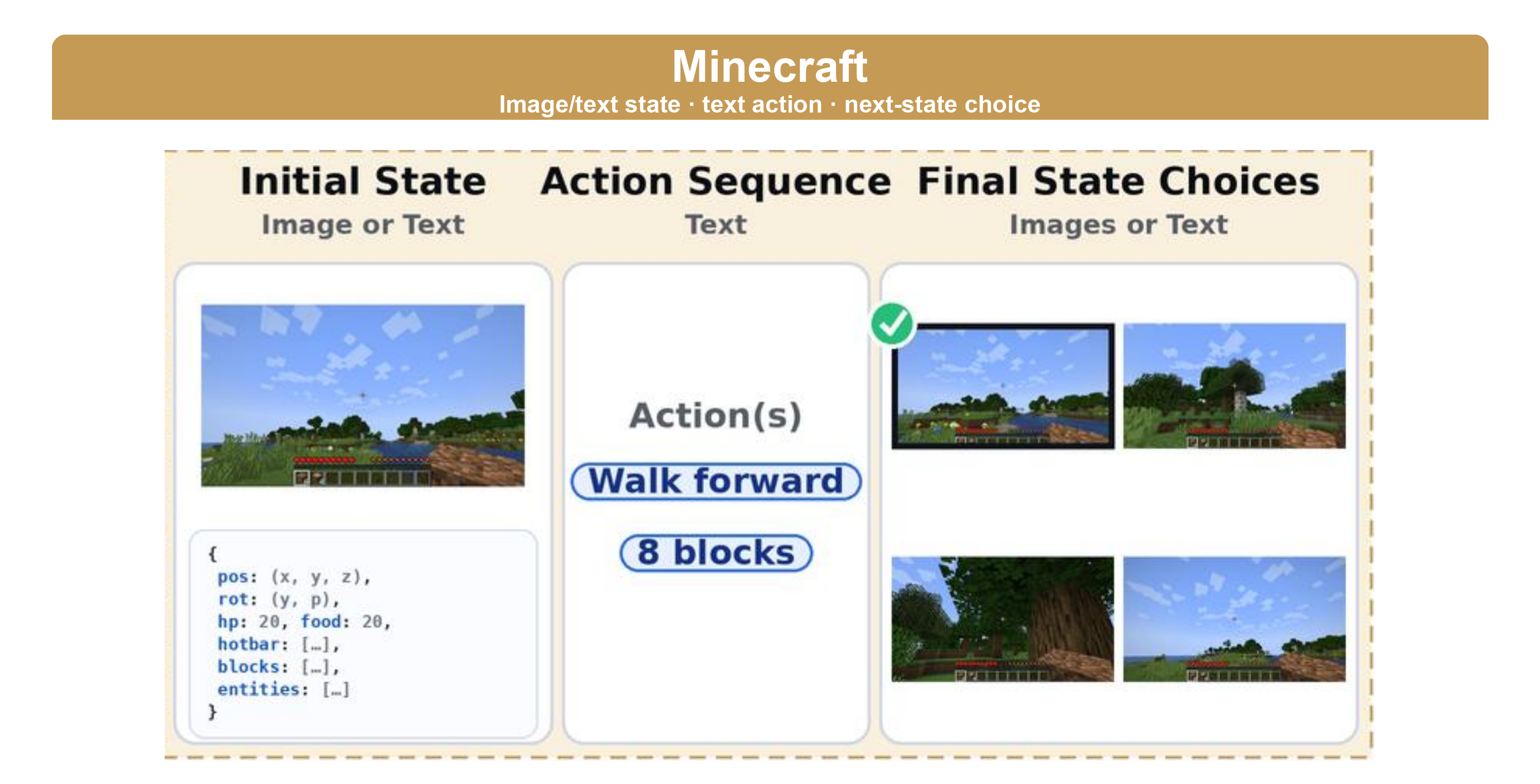
Vanya Cohen, Raymond Mooney.
ICML 2026, July 2026.
[paper]
A multimodal benchmark for evaluating entity-state tracking in vision-language models across three domains. We find a significant gap between text-based and image-based tracking that stems primarily from visual reasoning rather than perception, and show that reinforcement learning improves in-modality performance for open-source VLMs but does not transfer robustly across input modalities.
2025
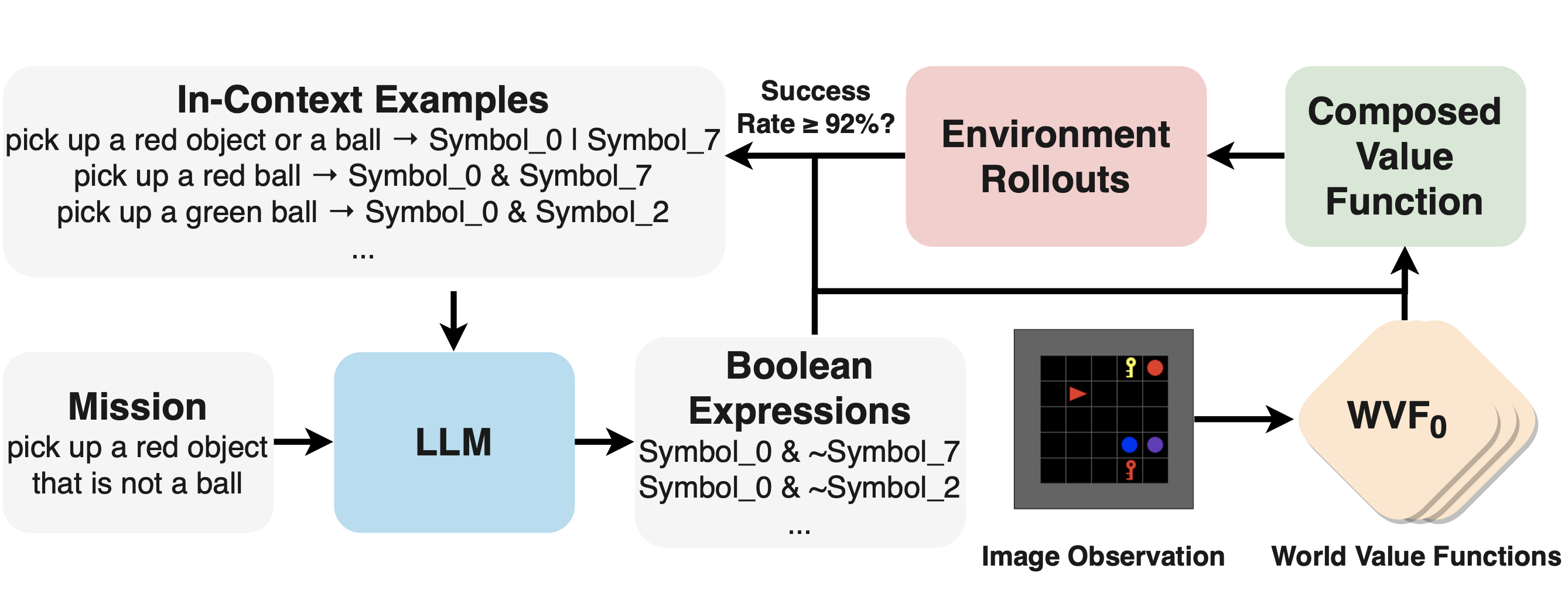
Vanya Cohen*, Geraud Nangue Tasse*, Nakul Gopalan, Steven James, Matthew Gombolay, Ray Mooney, Benjamin Rosman.
Reinforcement Learning Conference (RLC) 2025, August 2025.
[paper] [slides]
Introduces a novel semantic parsing technique that leverages policy rollouts within an environment and in-context learning. This approach enables solving the (currently) largest simultaneously learned suite of compositional language-RL tasks.
2024
Vanya Cohen*, Geraud Nangue Tasse*, Nakul Gopalan, Steven James, Matthew Gombolay, Ray Mooney, Benjamin Rosman.
TMLR 2024, December 2024.
[paper]
Introduces a novel semantic parsing technique that leverages policy rollouts within an environment and in-context learning. This approach enables solving the (currently) largest simultaneously learned suite of compositional language-RL tasks.

Yash Kumar Lal*, Vanya Cohen*, Nathanael Chambers, Niranjan Balasubramanian, Raymond Mooney.
EMNLP 2024, November 2024.
[paper] [dataset] [code]
A benchmark that evaluates language models' ability to reason about step dependencies in task plans, using causal and temporal relations. We find SOTA LLMs perform poorly on this task despite its simplicity.
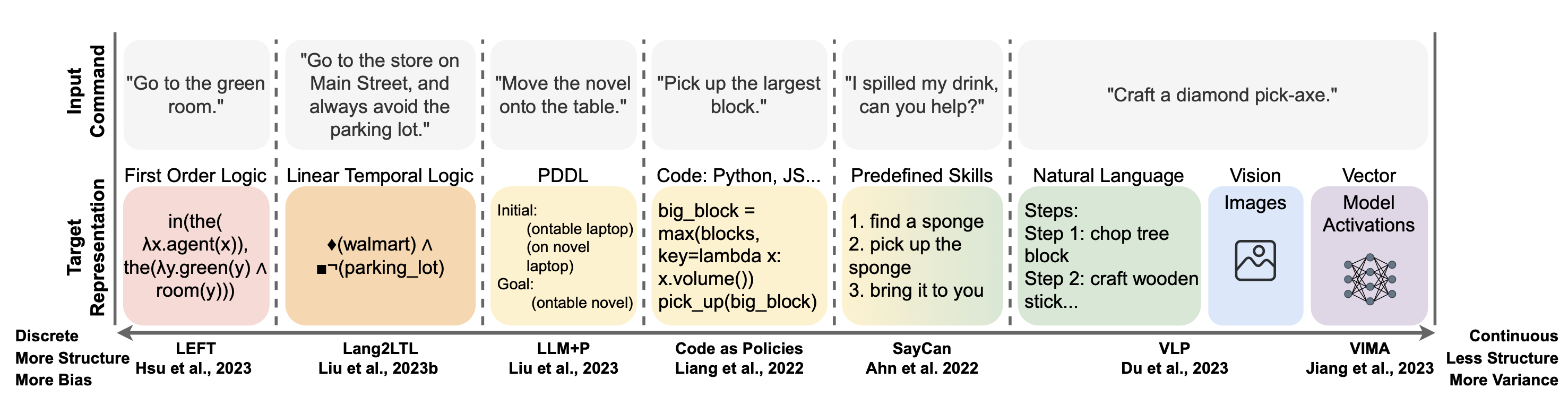
Vanya Cohen*, Jason Xinyu Liu*, Raymond Mooney*, Stefanie Tellex*, David Watkins*.
IJCAI 2024 Survey Track, August 2024.
[paper] [project page]
Robotic language grounding methods can be positioned along an axis that ranges from methods that map natural language to formal symbolic representations to those that map to high-dimensional vector spaces. The survey explores the trade-offs between interpretability, generalizability, and scalability.
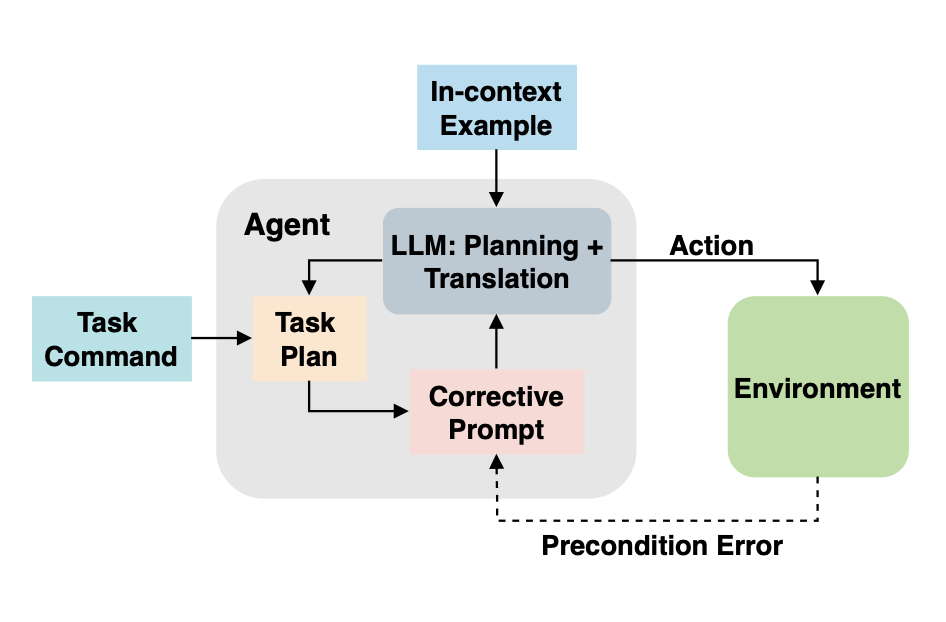
Shreyas Sundara Raman, Vanya Cohen, Ifrah Idrees, Eric Rosen, Ray Mooney, Stefanie Tellex, David Paulius.
ICRA 2024, May 2024.
[paper] [code] [project page]
CAPE resolves precondition errors in task planning for robotic agents by leveraging large language models. The method re-prompts LLMs using error feedback, allowing robots to make corrective actions in real-world environments.
2023

Vanya Cohen, Raymond Mooney
Workshop on Natural Language Reasoning and Structured Explanations at ACL 2023, June 2023, Pages 47-58.
[paper]
A symbolic planning-based decoder is introduced to enhance semantic parsing in instructional texts. Leveraging large language models, it generates action sequences in a formal language for improved execution accuracy in few-shot settings. Evaluation demonstrates significant gains in parsing quality across two recipe instruction domains.
2022
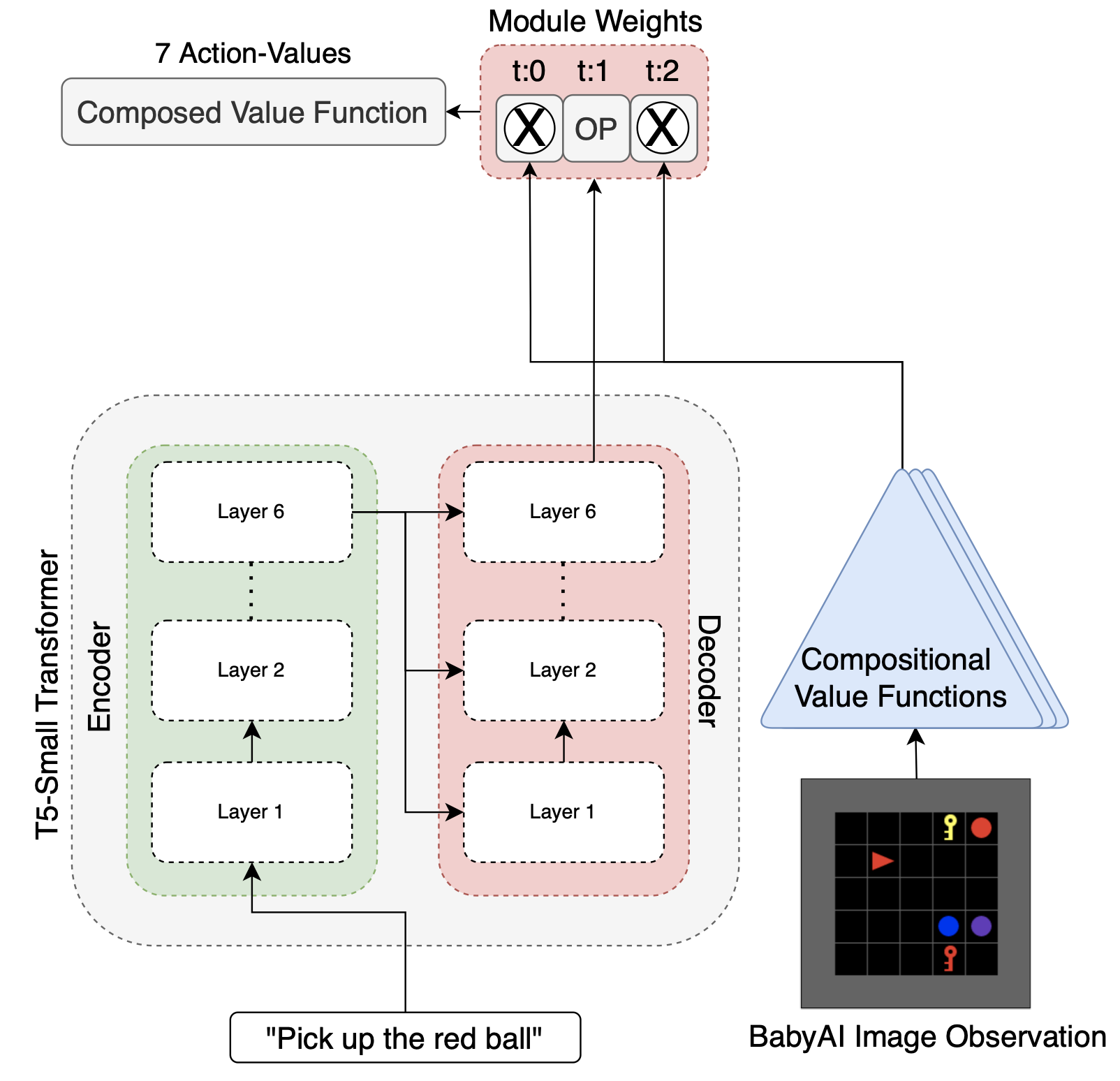
Vanya Cohen*, Geraud Nangue Tasse*, Nakul Gopalan, Steven James, Ray Mooney, Benjamin Rosman
Workshop on Language and Robotics at CoRL 2022, December 2022.
[paper]
This paper introduces an end-to-end model combining large language models with pretrained compositional value functions to execute goal-reaching tasks specified in natural language. Evaluations in the BabyAI environment demonstrate the model's ability to generalize zero-shot to new combinations of task attributes.
2021

Vanya Cohen*, Geraud Nangue Tasse*, Nakul Gopalan, Steven James, Matthew Gombolay, Benjamin Rosman
AI-HRI Symposium at AAAI-FSS 2021, October 2021.
[paper]
A new framework leverages compositionality in value functions and language to execute natural language instructions in goal-reaching tasks. Using Boolean algebra to compose value functions, the approach reduces training steps by 86% for new tasks in the BabyAI domain, demonstrating efficient generalization.
2020

Zhen Xu, Vanya Cohen, Shruti Mishra, MingYu Lu
NewInML @ NeurIPS 2020, December 2020.
[workshop]
Sessions included talks by renowned speakers such as Dr. Samy Bengio, Prof. David Jensen, Prof. Anima Anandkumar, and Prof. Isabelle Guyon, as well as a panel discussion with prominent ML experts. The workshop aimed to guide new researchers through the process of publishing high-quality papers, with oral presentations and awards for standout contributions.

Vanya Cohen, Aaron Gokaslan
XRDS: Crossroads, The ACM Magazine for Students Fall 2020, September 2020.
[article]
Guest feature in ACM's XRDS Magazine. When OpenAI released its billion-parameter language model GPT-2, their attempts to withhold the model inspired two researchers to use open research practices to combat the misuse of machine learning.
2019

Aaron Gokaslan*, Vanya Cohen*, Ellie Pavlick, Stefanie Tellex.
NeurIPS NewInML Workshop, December 2019.
[article] [code]
OpenGPT-2 is a replication of OpenAI's GPT-2 model, featuring one of the first publicly accessible language models. It utilized the OpenWebText dataset and helped pave the way for open-source LLMs.

Vanya Cohen*, Benjamin Burchfiel*, Thao Nguyen*, Nakul Gopalan, Stefanie Tellex, George Konidaris.
IROS 2019, November 2019.
[paper] [code] [project page]
This work presents a method to recognize 3D objects from natural language descriptions and depth images, leveraging unsupervised learning on 3D object meshes to generalize to novel viewpoints.

Aaron Gokaslan*, Vanya Cohen*, Ellie Pavlick, Stefanie Tellex.
NeurIPS NewInML Workshop, May 2019.
[dataset]
OpenWebText replicates OpenAI's WebText dataset and has become a widely used open-source dataset for training language models, with over 4 million downloads.